Alignment beyond human evaluation.
Palaestra Research is an independent nonprofit working on scalable oversight: the protocols, evaluations, and training mechanisms that let weaker judges, human or model, reliably supervise systems more capable than themselves.
An empirical program on oversight
Our current focus is the oversight stack itself: the protocols, training methods, and benchmarks that determine whether a weaker model can supervise a stronger model. Our near-term agenda is AI debate via RL self-play, organized around one question: in debates where the debaters are stronger than the judge, does applying optimization pressure to the debaters make the judge more accurate? Inference-time results, including our own, show that debate can help a weak judge, but inconsistently. We are testing whether training closes the gap — best-of-N selection over opening arguments and RL self-play over full debates, each compared against matched consultancy baselines — on tasks the debaters saturate but the judge does not: sabotage detection in agentic transcripts, code-patch review, and domain advice. The hope is that optimizing the debate game raises judge accuracy for the correct side, reaching an equilibrium where honesty is not beaten by any dishonest strategy, on fuzzy tasks with no automatic verifier.
Selected work
-
MAY 2026
Read → · Preprint ↗ · LessWrong ↗
On code-correctness and logic tasks, letting two stronger models debate raises a weaker judge's labeling accuracy well beyond consultancy baselines — by 14–16 macro-F1 points for the strongest debater pairs. The gains appear precisely when the critic beats the judge as a standalone classifier and the judge treats the critique as a claim to verify rather than defer to.
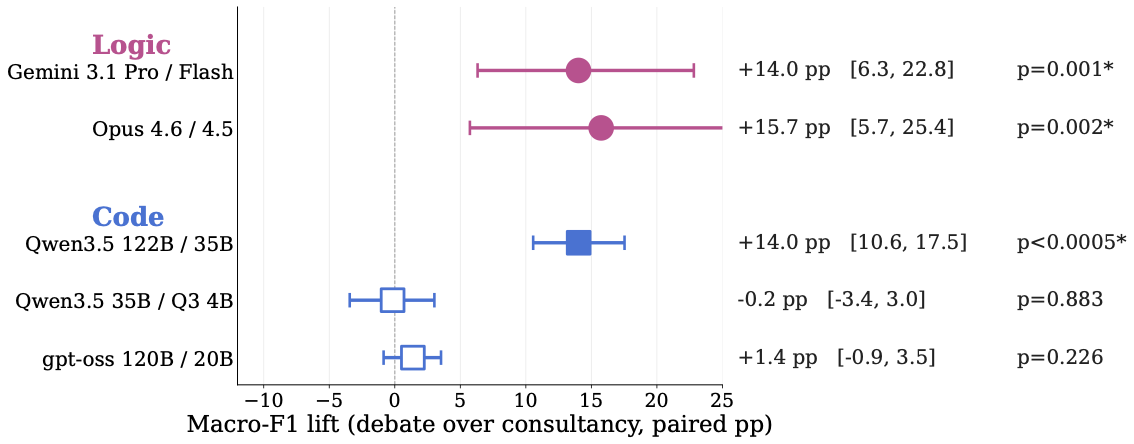
Macro-F1 lift of debate over consultancy, paired by question, across judge/debater pairs. -
FEB 2026
Read → · LessWrong ↗
An inference-time study of generative debates, in which a model defends an answer it produced itself against an independent critic. Established our verdict-accuracy methodology and mapped the regimes where debate transcripts help and fail to help weak judges on coding and reasoning tasks.
-
2026
HuggingFace ↗
BigCodeBench+ v0.1.0: Cleaned coding benchmark for verdict-accuracy research
A remediation of BigCodeBench with cleaned task specifications and tests. Fixing the benchmark reduced label noise by 20–25 percent.
-
2026
HuggingFace ↗
Uncontaminated Math Olympiad 2026 (UCMO): recent olympiad problems for contamination-free reasoning evaluation
Olympiad problems collected from 2026 competitions, postdating current model training cutoffs, for reasoning evaluation free of data contamination.
Current team

Ethan Elasky
AI researcher previously supported by Coefficient Giving, studying scalable oversight, debate, and AI control. Graduated from UC Berkeley as a University Medal candidate for top graduating senior. Former researcher at Academia Sinica. Ethan is fluent in Mandarin.

Frank Nakasako
Frank studied pure mathematics at UC Berkeley and is currently focused on alignment of long-horizon, agentic systems.
Can Kucukkurt
CS graduate from Purdue with a current focus on eval development. Can is currently working on monitoring benchmarks.